Online AI tools to make summaries (from major AI players) - October 20 2025
Sometimes, they can even summarize videos, but of course everything comes with a limit.
To know more about the limits of these AI chat bots, I tested them with a pdf document to check if an AI actually does a summary, then I asked the AI about its abilities.
There is however, a limit to this method: the AI is not necessarily aware of its own capabilities, since it has been trained on data of the past and doesn't necessarily have a search tool to get more recent information. It appeared very clear with "Qwen," which was the last AI chat bot that I tried, and where the data given by the settings menu contradicts the data given by the AI itself.
So, while this article should give you an overall idea of the capabilities of the models of some major AI players, the capabilities of these models and their offers are very likely to change. It can probably tell you which model to try first and give you information about features you may be not aware of. Gemini, Grok or Copilot are good choices, but there is no real bad choice in this list, unless you want to make a summary of a very big document...
I also understand from this, that the websites specialized in summaries that you can find online are probably not very interesting and should probably disappear since they are more specialized than a chat bot with more functionalities.
Google Gemini:
(based on Gemini's own answers)
Features of the Free Tier (General Access to Gemini 2.5 Flash):
- Context limit: 32,000 tokens (approx. 50 pages of text).
- Document Analysis: Can upload up to 10 files (docs/PDFs) per prompt, each ≤ 100 MB.
- Video Analysis: Limited to clips of up to 5 minutes total length per prompt.
- Deep Research: Limited access (e.g., ≈ 5 reports/month).
- Model Access: Default access to Gemini 2.5 Flash; limited access (e.g., ≈ 5 prompts/day) to the more powerful Gemini 3 Pro model.
Gemini's answers are a part of the context length, which seems to limit the size of the answer if your document length is close to the size limit.
Features of the Paid Tiers (Pro/Ultra - Access to Gemini 3 Pro):
- Context limit: 1 million tokens (approx. 1,500 pages of text)
- Document Analysis: Can process and summarize significantly larger single documents in one go. Required for spreadsheet/tabular data analysis.
- Video Analysis: Audio and visual frames. Total upload length for video analysis is up to 1 hour. Can use YouTube links (tested successfully, i used a paid account to test).
- Deep Research: Expanded access (e.g., ≈ 20 reports/day for Pro) using the more capable 3 Pro model (200 in Ultra).
- Model Access: Expanded, high-capacity access (e.g., ≈ 100 (pro) -500 (ultra) prompts/day) to the advanced Gemini 3 Pro model.
Google provides now a tool dedicated to summarize documents:
NotebookLM:
The following specifications of NotebookLM were provided by Gemini 3.
NotebookLM (cf wikipedia) is basically a tool based on the Gemini 2.5 Flash LLM (1.5 previously). It uses Retrieval-augmented generation (RAG) technology to query documents (this is my understanding of the tool).
Its inherent advantage over, for example, the usual Gemini 2.5 Flash, is that this tool is not supposed to hallucinate. It is required to use the documents you provide as its sole source of information. While I appreciate the tool's output, I am slightly skeptical of this claim. The drawback is that this model "thinks" less. NotebookLM seems capable of understanding text, audio, and graphics. It can use YouTube videos as a source, though it does not analyze the video frames themselves. It appears "Gemini 2.5 Flash" was selected over more recent models for its speed and cost efficiency. Besides text outputs, NotebookLM can generate video summaries (example 1, example 2), audio summaries, and "mind maps" (basically a tree chart of the document's ideas).
For both free and paid users, NotebookLM seems to have a context length of 1 million tokens (the chat's active memory). However, it can handle from 50 (free mode) to 300 (paid mode) documents of up to 500,000 words each, making it more interesting than standard Gemini for generating summaries.
As I mentioned, I am skeptical about the model's ability to avoid hallucinations because what the model reads can conflict with what it already knows. If you scroll down to the paragraph about Qwen3, you will see that the model thought "shoot" was a move in Rock-Paper-Scissors. If there is doubt about what a source explains, should the model correct it with outside knowledge? If yes, it may hallucinate. If no, and it is too strict, you end up with errors like "shoot" being a valid move.
In my second example, the NotebookLM video summary explained that my document is controversial. This implies it knows the document's identity and cultural significance—information that comes from the outside, unrelated to the text provided. If it ignores outside information, it might miss the article's point. But if it uses it, it risks hallucination. (For example, if I edit lines in the provided text, does the model know the original well enough to spot a forgery? When it claims a text is influential, it assumes the text is the original, even if I provided a forged version). Sorry, this was just to make a point, and I am not sure to what extent it matters.
Microsoft Copilot:
(based on Copilot's own answers)
Difference free tier/ paid tier: The abilities of Copilot to process and summarize isn’t different between free and paid accounts.
(Same amount of Tokens).
What can differ between account types are things like:
- Available features (e.g., access to certain modes like Deep Research or Think Deeper, or advanced customization tools)
- Speed and priority (premium users may get faster responses or earlier access to new features).
- Context limit: 10,000 of tokens IN ONE GO, that translates to dozens of pages of text (often 30–50+ pages of a standard academic paper).
If a document is longer than that, Copilot can still work with it, but it’s best to break it into sections for more precise summaries or analyses.
Copilots answers are a part of the context length, however its total context length is 32000, which is above the context length in one go.
Video Analysis: Can only use the text. (Tested with a mp4 and it didn't work)
Difference between the models:
- Quick response: for Fast, lightweight answers. Concise, surface‑level summaries; good for overviews or quick fact‑checks.
- Smart (GPT‑5): Adaptive, default advanced mode. Balances speed and depth; can shift between brief abstracts and nuanced, multi‑layered summaries depending on complexity.
- Think Deeper: Careful, reflective reasoning. Slower but more thorough; breaks down arguments step‑by‑step, highlights ambiguities, and explores implications.
- Deep Research: Extended web‑based investigation. Produces long, citation‑rich reports; ideal for comprehensive literature‑style summaries.
ChatGPT:
(based on ChatGPT's own answers)
Difference between the models and the account type:
- Account Type: Free (GPT-3.5), Context / Token Limit: ~16,000 tokens, Approx. Words / Pages: ≈ 12,000 words (30–40 pages), can't handle very long pdf.
- Account Type: GPT-4 (early API, rarely used), Context / Token Limit: 8 k – 32 k tokens, Approx. Words: 6 k – 24 k words.
- Account Type: Plus / Pro (GPT-4-Turbo or GPT-5), Context / Token Limit: ~128,000 tokens, Approx. Words / Pages: ≈ 90,000–100,000 words (250–300 pages), Handles long texts, codebases, and big PDFs easily
- Account Type: Enterprise / Team tiers, Context / Token Limit: up to ~200 k+ tokens, Approx. Words: ≈ 150,000+ words, Easily handles books & reports, Configurable depending on contract.
ChatGPT answers are a part of the context length, limiting the output if you submit a document that is close in size from the context length.
Video Analysis: Claim to only use the text or the transcript. Accepted a Youtube link and started to analyze it's frame one by one (not like Gemini or Qwen), as a free user, it finally returned this answer: "The video was too long for a single processing pass — it hit the 60-second limit before finishing."
Difference between the modes (e.g., “Thinking,” “Deep Search,” “Data Analysis”): there is no difference of token length:
- Thinking mode: spends more internal reasoning time on the same text limit.
- Deep Search mode: can retrieve and integrate info from the web or files, but each step still fits within the same token window.
- Data Analysis (Python) mode: can handle larger files by processing them in chunks, not by increasing the per-message token limit.
Claude from Anthropic:
(Based on Claude Sonnet 4.5 's own answers)
Claude doesn't claim to have any specific information about context length differences between free and paid Claude accounts.
Claude Sonnet 4.5 claims to have a token budget of 190 000 tokens. It claims that it is about 300 to 400 pages of text.
(I used a paid amount).
When asked if there is a distinction of context length between the model, the AI made a distinction between the "3" and the "4" models.
Claiming that the "3" models have a context length of 200 000 tokens, but then it didn't give any real data for the "4" models.
Claiming that Anthropic typically maintains or increases the context windows with new generations.
(But logically it went from 200 000 to 190 000)...
Claude answers are a part of the context length. So if submitted a text of 185000 tokens, it won't produce an answer longer than about 1500-2250 tokens.
Claude typically stops to answer when you exceed its context length (that's how I understand Claude's behavior).
Video Analysis: not really. Can only use the text or the transcript, or images (including several images). Try to check the content frame by frame, when interrogated about a video (very slow). Returned a wrong answer to my question.
Question: When do we see a FIST for the first time in this video ? (i uploaded the mp4 of it)

Grok:
(Based on Grok's own answers)
I found Grok to be the most useful/synthetic to understand the document, but I like numbers. If you like more textual answers, then Grok is maybe not the best for you (but Grok3 used to be very chatty for other purposes, may be even too chatty...).
When asked if there is a size limit to what Grok can summarize, it answers "no" but continues to speak about the text, while it is no more the topic. However, when the context is specified, Grok answers accurately.
For both Grok-4 and Grok-3, the context limit of 128,000 tokens applies universally, whether you're on a free or paid plan. Free accounts have the same core capabilities (e.g., summarization, tool use, multi-modal processing) as paid tiers, but usage is restricted by quotas (e.g., number of tokens or requests per day/month). Some variants of grok3 had a context window of 1 million tokens, while some variants of Grok4 have a context window of 256000 tokens and some other (premium tier) have a context window of 2 millions tokens.
- Video Analysis: both Grok4 and Grok3 can access to video content, but according to Grok (what version?), Grok4 has better visual scene interpretation capabilities. Grok3 uses mostly the text. It can access to platform videos (youtube, vimeo...). As a free user, "grok 4 fast" tells me that mp4 are not allowed when i try to analyze a video. When I give a Youtube link, as a free user, it seems to analyze the audio, even with "Grok 4 fast".
Grok answers are a part of the context length, however Grok claims to not have a real limit of context:
- to summarize (cutting the documents in chunks of data)
- to answer (individual answers can reach 8,000–16,000 tokens, but Grok can extend summaries across multiple messages or use chunking for larger outputs, so the context limit doesn’t strictly cap answer size—it just manages the conversation scope)
- and to process videos (but practical limits arise from processing time and quota constraints). (note: that's Grok's claim)
Perplexity.ai
(Based on Perplexity's own answers)
Perplexity's summary was interesting.
Perplexity's abilities are different in free mode and in pay mode.
- Free accounts can process up to ≈ 8,000 tokens per query (roughly 20000 characters, or about 3000 words).
The free tier generally provides access to earlier, less powerful models such as GPT-4.1 and Perplexity’s in-house base model R1 (fine-tuned from LLaMA 3.1 7B), plus Claude 4.0 Sonnet .
- Pro (Complexity) accounts can handle far larger contexts — up to around 128000 tokens per query, depending on the model used (Complexity/Comet tier). Paid tiers also support file search, multi‑source retrieval, and multi‑document summarization, allowing long reports or academic PDFs (well over 100 pages) to be processed by chunking them automatically into context segments.
The paid tier uses GPT-5, Claude 4.5 Sonnet, Gemini 2.5 Pro, Sonar Large (Perplexity’s proprietary, optimized large LLaMA 3.1 70B model).
Perplexity's answers are a part of the context length, limiting the output if you submit a document that is close in size from the context length, however since Perplexity uses multi-chunking in paid mode, I think it should only matter in the free mode.
- Video Analysis: Besides video upload, both free and paid versions support summarizing videos from popular platforms like YouTube and Vimeo, primarily by accessing or utilizing the video transcripts rather than the raw video frames. In free mode, the system does not directly analyze video frames or visual content. Instead, it relies on transcripts or captions extracted from the video to generate summaries.
- Size limit in free mode: 40mb, 10 files maxi.
- The pay (pro) mode includes multimodal video processing capabilities such as uploading video files for frame-by-frame analysis, visual scene understanding, and combining visual and audio information for richer summaries and insights. This multimodal processing is available via API and integrated tools. No size limit given.
Deepseek
(based on Deepseek's own answers)
Deepseek is mostly free of charge for the user, but charges businesses and developers when they use Deepseek's API.
Deepseek says it is free:
- for user acquisition: to building a large user base quickly
- for technology development: More users = more data to improve the models
- for market position to compete with other free AI services
- for ecosystem building: to create a platform that developers and businesses will pay to access
Deepseek has a general context limit of 128k tokens and its answers are a part of the context size.
Deepseek claim to be able to use chunking for bigger files, however it suggests:
- or to do the chunking manually.
- or to start to summarize the first 128k (in fact it would be more 100k, since its answers account in the context length).
then summarize the remaining section specifically.
- or to focus the analysis on some parts of the text only.
In my opinion, that's not real file chunking.
Deepseek can't do video summaries directly and can't access online platforms like youtube or vimeo, you have to upload the video.
Deepseek claims that it can then do some ocr on the frames but can't analyze the audio or the video besides this.
DeepSeek uses the DeepSeek-V2 model.
Qwen online
Qwen is an AI developped by AliBaba. It is free and has a pay-as-you-go model: pricing is based on tokens used per request, not monthly subscriptions. 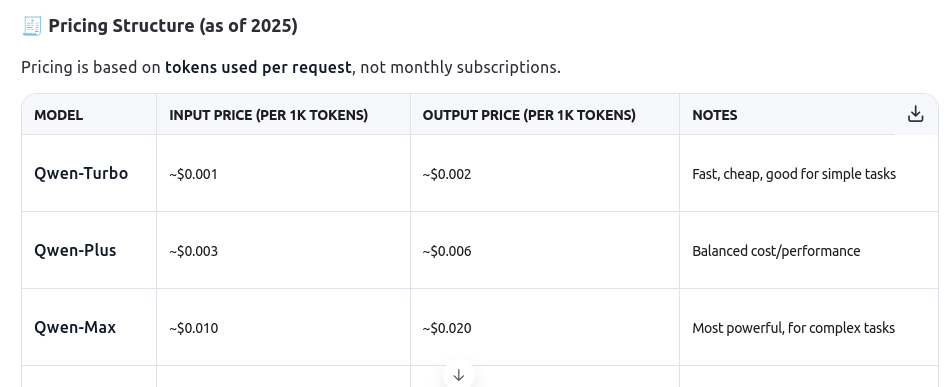
However the data given by Qwen3 is contradictory, telling me that the free tier is not available for Qwen3-Max while I was using it (see below).
Be cautious with Qwen3, because it gave wrong answers about itself and about who it was: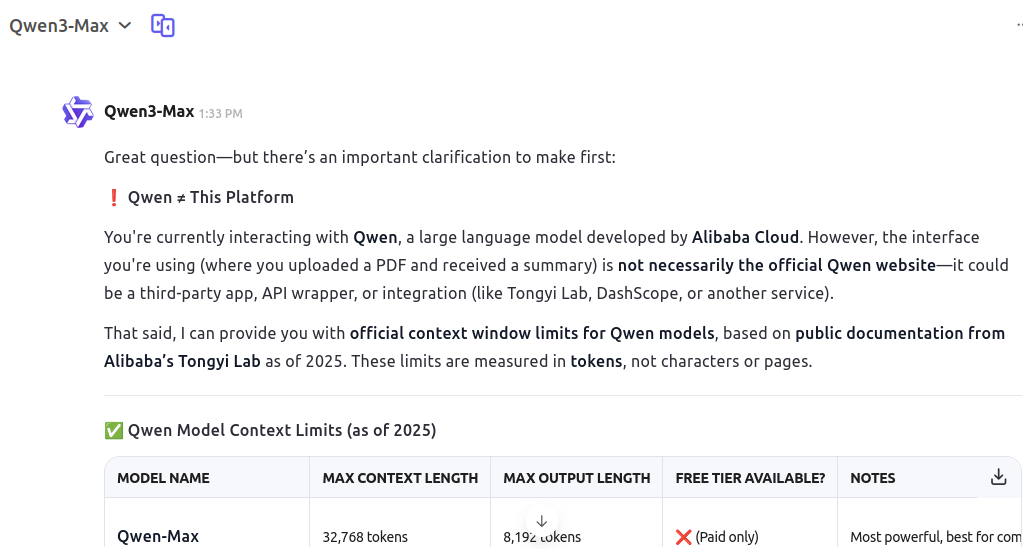
So here, I am not supposed to be able to use Qwen-Max (free tier), while the chat (beginning) clearly stated that I was using "Qwen Max".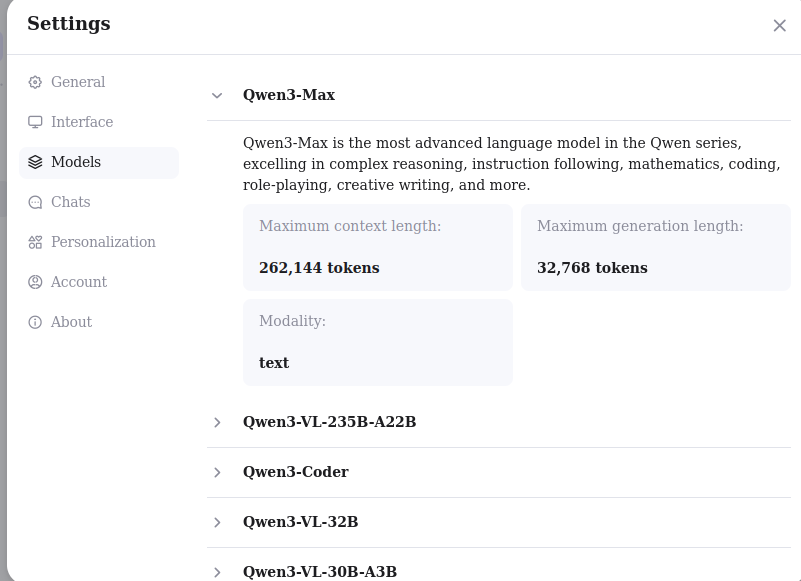
Compare now the 2 pictures, they give contradictory information: one time my max context length is 32768 tokens and the other time it is 262144 tokens.
So while Qwen's summary was very decent, I don't like this kind of discrepancies because it also suggests that something is, or not consistent, or not up-to-date.
So for Qwen, and according to Qwen's own claims, even the VL models (visual) can't process videos. It is even not recommended to submit more than 3 pictures!:
Qwen3 told me to have a context length of 32768 tokens, but the settings menu gave much better capabilities for Qwen3. I guess there is no point to discuss more about the capabilities of Qwen3 according to Qwen3 itself, if its answers are doubtful.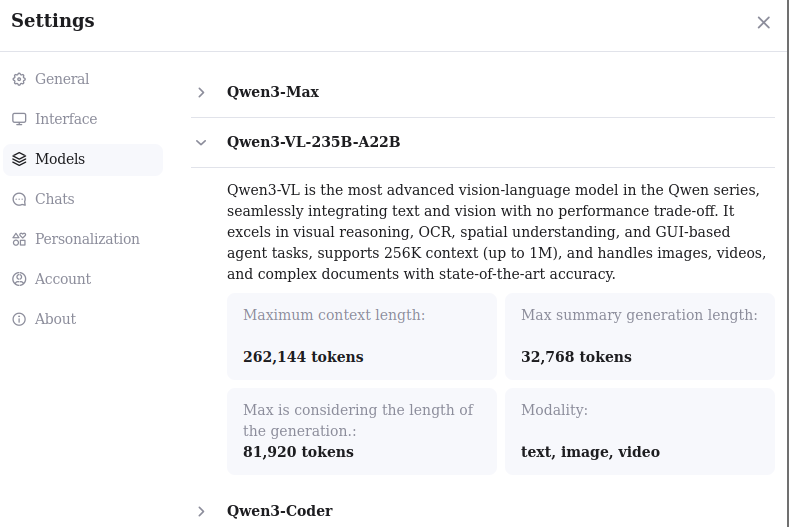
So can Qwen3-VL-235B-A22B handle videos as stated in this menu but in contradiction with what Qwen3 says ?
When tested on this video that explains what is the game "rock, paper, scissor" it seems that both Qwen3-VL-235B-A22B:
and even Qwen3 max understand what is happening in the video:
Suggesting that Qwen3 is much better than what it claims to be when you ask it about itself. However the "shoot!" move doesn't exist in the video and is a wrong interpretation of Qwen. However, from this list, i was only able to test 2 tools that can understand videos: Gemini (imo better) and Qwen (I didn't have an account to test this with Perplexity.ai), so Qwen is not that bad even if it can be improved.